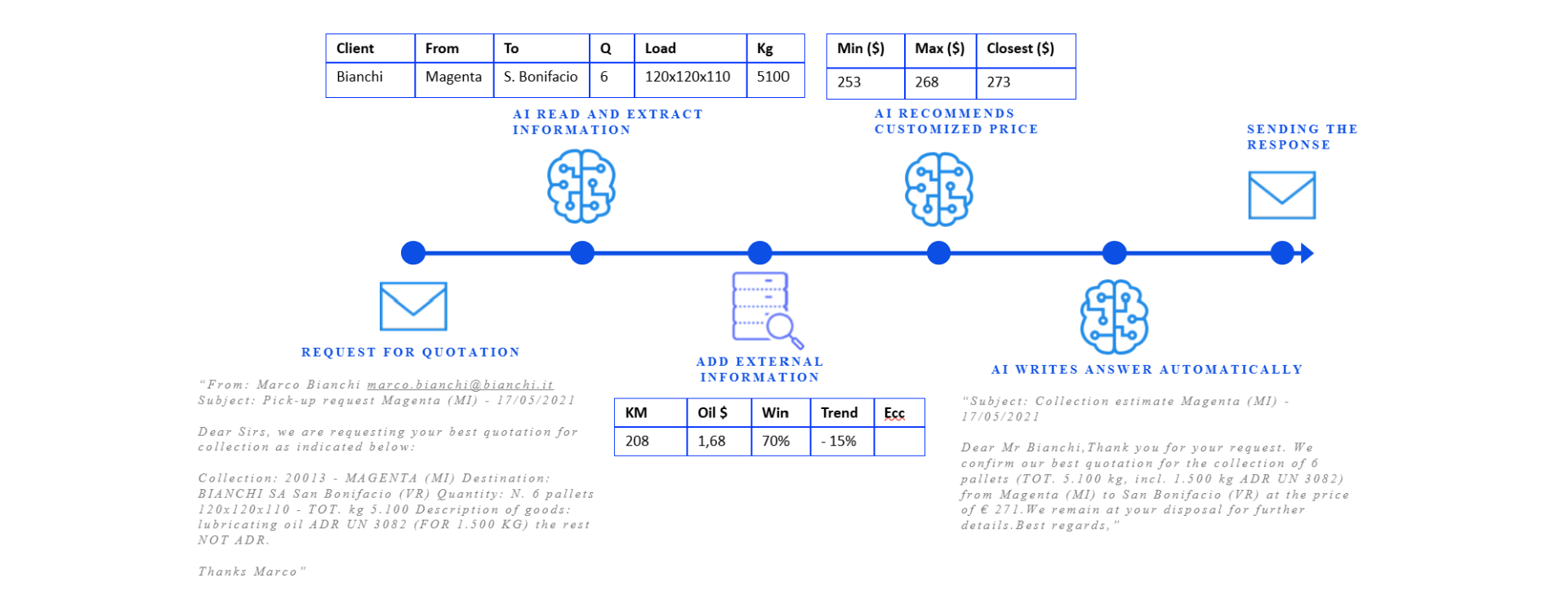
AI-based Predictive Maintenance of Switches

“Before this project, the idea of predicting hardware failures in our RTN infrastructure felt unrealistic. But Artificialy proved that meaningful foresight is not only possible, it's practical. The system identified upcoming malfunctions days in advance, giving our engineers more time to respond and prevent disruption. It’s a promising step toward more proactive and intelligent infrastructure management, and we're excited about where it can go from here.”
Challenge
The client manages an RTN network that forms the backbone of its infrastructure, ensuring reliable delivery of video, data and internet services. This high-capacity system depends on dozens of critical switches. Failures or degraded performance in any of these switches can lead to poor customer experience and, in the worst case, to complete service interruptions.
While the client had recently implemented a new monitoring system tracking hundreds of metrics per switch, they lacked any way to anticipate problems before they became critical.
With large volumes of high-frequency data but no predictive tools, they needed an AI-driven approach to shift from reactive to proactive maintenance.

A media & entertainment player: one of the most famous Swiss radio and television operating in the Italian-speaking part of Switzerland.

Our AI Solution
Over a few months, we developed a custom-built anomaly detection engine designed to identify early warning signs of hardware failures across critical RTN infrastructure.
Each monitored switch streams around 800 features, including CPU usage, interface traffic, temperature, power metrics, and more. This results in gigabytes of high-frequency telemetry data spread across switches of different types and configurations.
The solution was designed to address three core goals:
Scalability: the system efficiently processes large volumes of time series data, even with irregular sampling rates and gaps, and can be quickly adapted to support additional switches or new switch types.
Tailored Detection: the solution applies custom logic for each switch type and each event type, enabling precise detection of different malfunctions while minimizing false or irrelevant alerts.
Explainability: for every warning, the model highlights exactly which metrics showed abnormal behavior, enabling engineers to understand and verify anomalies without relying on black box predictions.
The system was deployed into the client's internal environment, where it now integrates with their monitoring stack to deliver real- time alerts for potential switch malfunctions.
Results
While Artificialy’s solution is still under evaluation in production, offline testing has already shown strong potential:
~50% of critical events detected , with an average of 11 days lead time, giving engineers valuable time to investigate and prevent service disruptions.
~50% false alerts , aligned with the client’s operational capacity for manual review,
Scalable foundation: this solution lays the groundwork for future development, including severity scoring, automatic fine tuning, and advanced models.

You may also be interested in
AbaClik: your AI-powered voice assistant for back office operations